목차
CIFAR-10 분류 모델 97.78% 달성하기
본 실험은 CIFAR-10 데이터셋을 이용한 이미지 분류 태스크에서 모델의 일반화 성능을 극대화하기 위한 단계별 최적화 과정을 기술한다. LeNet-5 기반의 베이스라인 모델(정확도 약 61.25%)에서 출발하여, 모델의 표현력을 높이기 위해 ResNet, WideResNet, PyramidNet 등 다양한 심층 신경망 아키텍처를 도입하고 그 효율성을 비교 분석하였다.
단순한 모델의 깊이 확장보다 넓은 채널 폭을 가진 구조가 효율적임을 확인하였으며, 과적합 방지와 학습 안정성을 위해 AutoAugment, CutMix 등의 데이터 증강 기법과 Cosine Annealing 스케줄러를 적용하였다. 특히, 최적화 관점에서 Adam 대신 Nesterov Momentum을 적용한 SGD로의 전환, 손실 지형의 평탄함을 찾는 ASAM(Adaptive Sharpness-Aware Minimization), 학습 가중치의 이동 평균을 사용하는 EMA(Exponential Moving Average), 그리고 Label Smoothing 기법을 결합하여 성능을 대폭 향상시켰다.
최종적으로 PyramidNet-110 아키텍처에 ShakeDrop 정규화를 적용하고 400 Epoch 동안 학습하여 단일 모델 성능을 극대화하였으며, 앙상블(Ensemble) 및 메타 러너를 활용한 스태킹(Stacking) 기법을 도입하여 97.78%의 최종 정확도를 달성하였다. 본 실험을 통해 아키텍처의 구조적 개선뿐만 아니라, 최적화 알고리즘과 정규화 전략의 조화가 고성능 모델 구현에 필수적임을 입증하였다.
본 실험에 사용된 전체 소스 코드와 실험 로그는 GitHub 저장소에서 확인할 수 있다.
개요
CIFAR-10 데이터셋은 10가지 종류의 사물 이미지가 담긴 머신러닝용 이미지 데이터셋으로 각 32x32 픽셀 크기의 컬러 이미지 60000장으로 구성된다. 총 60,000장 중 50,000장은 훈련용으로, 10,000장은 테스트용으로 사용된다.
로딩 중...
Baseline
로딩 중... Caption: Baseline Code
Caption: Baseline Code
LeNet-5를 기반으로 한 CNN 모델을 베이스라인으로 선정하였다. 합성곱층과 풀링층을 반복하여 특징을 추출하고, FC 층을 통해 분류를 수행하는 기본적인 구조이다. 최적화 알고리즘으로는 수렴 속도를 고려하여 Adam을 채택하였으며, 구체적인 학습 하이퍼파라미터는 다음과 같다.
- Epochs: 20
- Batch Size: 128
- Learning Rate: 3e-4 (Andrej Karpathy는 "A Recipe for Training Neural Networks"를 통해 Adam 옵티마이저 사용 시 3e-4를 안전한 시작점으로 언급함)
- Seed: 42
실험 결과
베이스라인 모델의 성능을 측정하고, 가중치 초기화 기법의 영향력을 검증했다. ReLU 활성화 함수를 사용하는 신경망에서는 가중치가 적절히 초기화되지 않을 경우 그레디언트 소실이나 폭주가 발생할 수 있다. 이를 방지하기 위해 **He Initialization (Kaiming Normal)**을 적용했다.
| Model Setup | Best Val Acc (%) |
|---|---|
| Baseline (Adam Optimizer) | 59.48 |
| + Weight Initialization (Kaiming) | 61.25 |
실험 결과, 기본 초기화 방법 대비 Kaiming Initialization을 적용했을 때 약 1.77%p의 성능 향상이 관찰되었다.
로딩 중...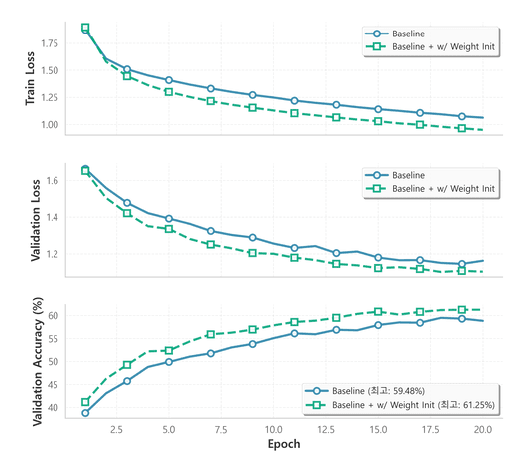
개선 전략 및 설계
베이스라인 모델은 얕은 구조로 인해 CIFAR-10 데이터의 복잡한 패턴을 충분히 학습하지 못한다. 이에 따라 모델의 표현력을 높이기 위해 다음 전략을 수립하였다.
Deeper Baseline
성능 개선의 핵심은 모델의 깊이와 너비를 확장하는 것이다. 컨볼루션 층을 더 추가하여 고차원 특징을 추출하도록 유도하였으며, 정보 손실을 최소화 하기 위해 필터수를 늘렸다.
로딩 중... Caption: DeepBaselineNet Code
Caption: DeepBaselineNet Code
성능 개선을 위해 모델의 깊이와 채널의 수를 대폭 증가 시켰다.
실험 설정
Network: DeepBaselineNet
Optimizer: Adam
Epochs: 20
Batch Size: 32
Learning Rate: 3e-4
모델이 깊어짐에 따라 발생할 수 있는 학습 불안정성과 과적합 문제를 해결하기 위해 단계적으로 개선 기법을 적용하였다.
- Weight Initialization: 앞선 실험에서 유효성이 입증된 Kaiming Initialization을 기본으로 적용하였다.
- Batch Normalization: 학습 과정에서 각 층의 입력 분포가 변하는 현상을 완화하여, 학습 속도를 높이고 초기화 민감도를 낮추었다.
- Cosine Annealing: 학습이 진행됨에 따라 학습률을 점진적으로 감소시켜, 최적점 부근에서 안정적으로 수렴하도록 유도하였다.
실험 결과
로딩 중...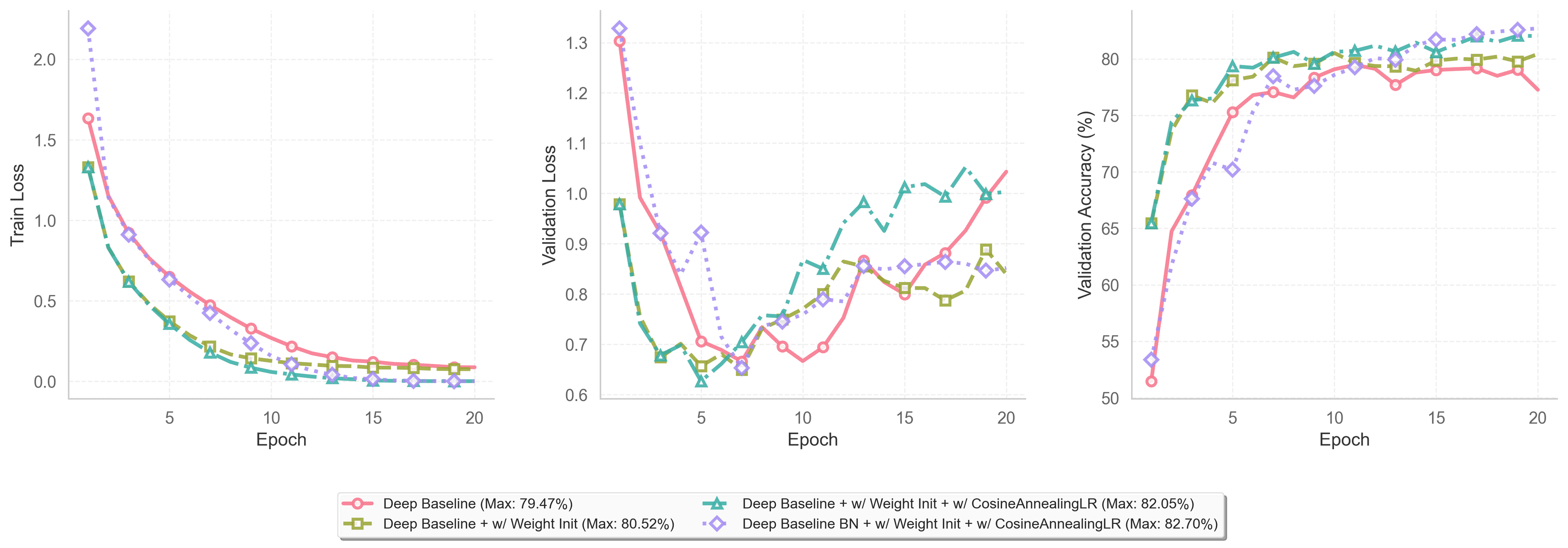
| 실험 조건 (Modifications) | Best Val Accuracy (%) |
|---|---|
| Deep Baseline (Adam, 3e-4) | 77.27 |
| + Weight Initialization (Kaiming) | 80.52 |
| + Cosine Annealing LR | 82.05 |
| + Batch Normalization | 82.70 |
기법을 하나씩 추가할 때마다 정확도가 뚜렷하게 상승했다. 가중치 초기화를 통해 베이스라인 대비 큰 폭의 성능 향상을 보였으며 이는 초기 가중치 설정이 중요함을 입증했다. Cosine Annealing 적용 후 발생했던 Validation Loss의 변동을 Batch Normalization을 통해 어느 정도 억제할 수 있었다. 모든 모델에서 10 Epoch 이후로 Validation Loss가 다시 증가하거나 정체되는 과적합 문제가 발견되었다.
Augmentation
로딩 중...
모델의 구조적 개선 이후, 과적합을 방지하고 일반화 성능을 극대화하기 위해 다양한 데이터 증강 기법을 적용하였다. 본 실험부터는 모델의 수렴을 충분히 보장하기 위해 학습 에포크를 100 Epochs로 확장하였다.
사용된 주요 증강 기법의 정의는 다음과 같다.
- Standard Augmentation: 기본적인 기하학적 변환으로,
RandomCrop(padding=4),RandomHorizontalFlip,RandomRotation(15)를 포함한다. - CutMix: 이미지의 일정 영역을 잘라내어 다른 이미지의 패치로 채우고, 라벨 또한 면적 비율에 따라 혼합하는 기법이다.
- Mixup: 두 이미지의 픽셀 값을 비율에 따라 선형적으로 섞고 라벨도 동일하게 섞는 기법이다.
- AutoAugment: 강화학습(RL)을 통해 데이터셋(CIFAR-10)에 가장 적합한 증강 정책(Policy)을 자동으로 탐색하여 적용하는 기법이다.
- Cutout: 이미지의 임의의 사각형 영역을 검은색(0) 등으로 마스킹하여 모델이 특정 특징에만 의존하지 않도록 하는 정규화 기법이다.
실험 설정
- Model: DeepBaselineBN (10.4M Params, Kaiming Init)
- Training: Adam (LR 3e-4), Cosine Annealing (100 Epochs)
실험 결과
| 어그먼테이션 조합 | Best Val Acc (%) |
|---|---|
| Baseline (No Augmentation) | 78.43 |
| Standard Augmentation (SA) | 90.01 |
| SA + CutMix | 90.26 |
| SA + CutMix (start at 75%) | 89.49 |
| SA + Mixup | 89.85 |
| SA + Cutout | 90.11 |
| SA + Cutout + AutoAugment | 90.52 |
| SA + Cutout (Len 8) + AutoAugment | 89.86 |
| SA + CutMix + AutoAugment | 90.88 |
| SA + Mixup + AutoAugment | 90.43 |
| SA + AutoAugment | 91.17 |
아무런 증강을 하지 않았을 때(78.43%) 대비, 기본적인 Standard Augmentation만 적용해도 정확도가 **90.01%**로 급격히 상승(약 +11.5%p)하였다. AutoAugment를 단독으로 추가했을 때 **91.17%**로 가장 높은 성능을 기록하였다. 이는 사람이 수동으로 설정한 정책보다 데이터셋에 최적화된 정책이 효과적임을 보여준다.
Deeper Model And Residual Connection
로딩 중... Caption: DeepBaseline3BNResidual Code
Caption: DeepBaseline3BNResidual Code
모델의 층이 깊어질수록 학습 데이터에 대한 오차가 오히려 증가하는 Degradation 문제와 기울기 소실 문제를 해결하기 위해, ResNet(He et al., 2015)의 핵심 개념인 **잔차 학습(Residual Learning)**을 도입하였다.
기존 모델이 입력 x를 출력 H(x)로 직접 매핑하려 했다면, 개선된 모델은 잔차함수 F(x) := H(x) - x를 학습하는 것을 목표로 한다. 최종 출력은 H(x) = F(x) + x가 되며, 이는 다음과 같은 이점을 제공한다.
- Gradient Flow: 역전파 시 덧셈 연산을 통해 그래디언트가 하위 레이어로 직접 전달(Shortcut)되어 학습이 안정적이다.
- Identity Mapping: 모델이 더 깊어져도, 추가된 레이어가 항등 함수(Identity Mapping)를 쉽게 학습할 수 있어 성능 저하를 방지한다.
아키텍처 변화
기존 DeepBaselineNetBN 대비 채널 수를 대폭 확장(Max 256 -> 512)하였으며, 단순 Conv 레이어를 Residual Block으로 대체하였다.
| Layer Stage | Component / Block Type | Channels |
|---|---|---|
| Stem | Conv (3x3) + BN + ReLU | 3 -> 64 |
| Block 1 | Residual Block (Identity) | 64 -> 64 |
| Block 2 | Residual Block (Identity) + MaxPool | 64 -> 128 |
| Block 3 | Residual Block (Identity) | 128 -> 256 |
| Block 4 | Residual Block (Identity) + MaxPool | 256 -> 256 |
| Block 5 | Residual Block (Identity) + MaxPool | 256 -> 512 |
| Classifier | Flatten to FC Layers (Dropout 0.1) | 512 -> 10 |
실험 결과 (Residual + AutoAugment)
| Model | Best Acc (%) | Params | GFLOPs |
|---|---|---|---|
| DeepBaselineBN | 91.17 | 1.9 M | 0.1 GFLOPs |
| DeepBaselineNetBN3Residual | 94.65 | 10.4 M | 1.1 GFLOPs |
이전 단계에서 DeepBaselineNetBN에 AutoAugment를 적용했을 때의 최고 성능은 **91.17%**였다. 여기에 Residual Connection 구조를 도입하고 채널 수를 확장한 결과, 정확도가 94.65%로 대폭 향상(+3.48%p)되었다.
Deeper And Deeper
모델 설계
- Multi-Stage Architecture: 단순히 레이어를 나열하던 방식에서 벗어나, 채널 수에 따라 4개의 Stage로 구분하고, 각 Stage마다 다수의 Residual Block을 적층하는 방식을 채택하였다. (총 15개의 Residual Block)
- Global Average Pooling 도입: 기존 모델은
Flatten후 거대한 FC Layer를 사용하였으나, 이번 모델에서는 마지막 Stage 출력값에 평균 풀링을 적용하여 (1x1) 크기로 압축하였다.
실험 결과
| Model | Best Acc (%) | Params | GFLOPs |
|---|---|---|---|
| DeepBaselineBN | 91.17 | 1.9 M | 0.1 |
| DeepBaselineNetBN3Residual | 94.65 | 10.4 M | 1.1 |
| DeepBaselineNetBN3Residual15 | 94.84 | 13.5 M | 0.71 |
이전 모델 대비 파라미터 수는 약 30% 증가하고 연산량 또한 크게 늘었으나, 정확도 향상은 +0.19%p에 그쳤다. 더 이상의 단순한 깊이 확장은 연산 비용 대비 효율이 떨어지므로 다른 접근법이 유효할 것으로 판단된다.
Wider Model (WideResNet)
로딩 중... Caption: WideResnet16-8 Code
Caption: WideResnet16-8 Code
ResNet 구조 실험을 통해 깊이가 성능에 기여함을 확인했으나, 층이 너무 깊어지면 학습 속도가 저하되고 파라미터 효율이 떨어지는 문제가 있었다. 이를 해결하기 위해 **Wide Residual Network (WRN)**를 도입하였다.
Pre-activation 및 구조
He et al.(2016)이 제안한 Pre-activation ResNet 구조(BN -> ReLU -> Conv)를 따르며, 넓어진 채널로 인한 파라미터 과적합을 막기 위해 Dropout을 삽입하였다.
로딩 중...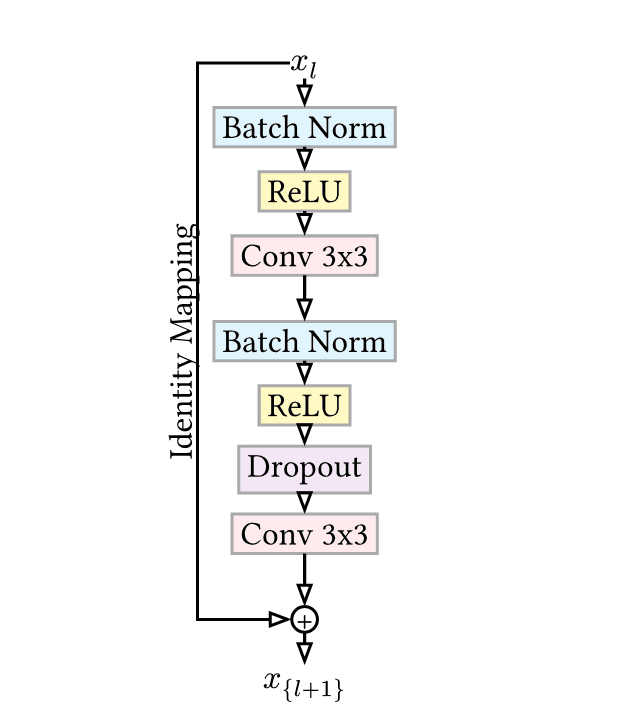
Widen Factor
기본 ResNet 블록의 채널 수에 확장 계수 k=8을 곱하여 필터(Filter)의 수를 대폭 늘렸다.
WideResNet-16-8은 전체 깊이가 16이며, 3개의 주요 그룹으로 구성된다.
실험 결과
로딩 중...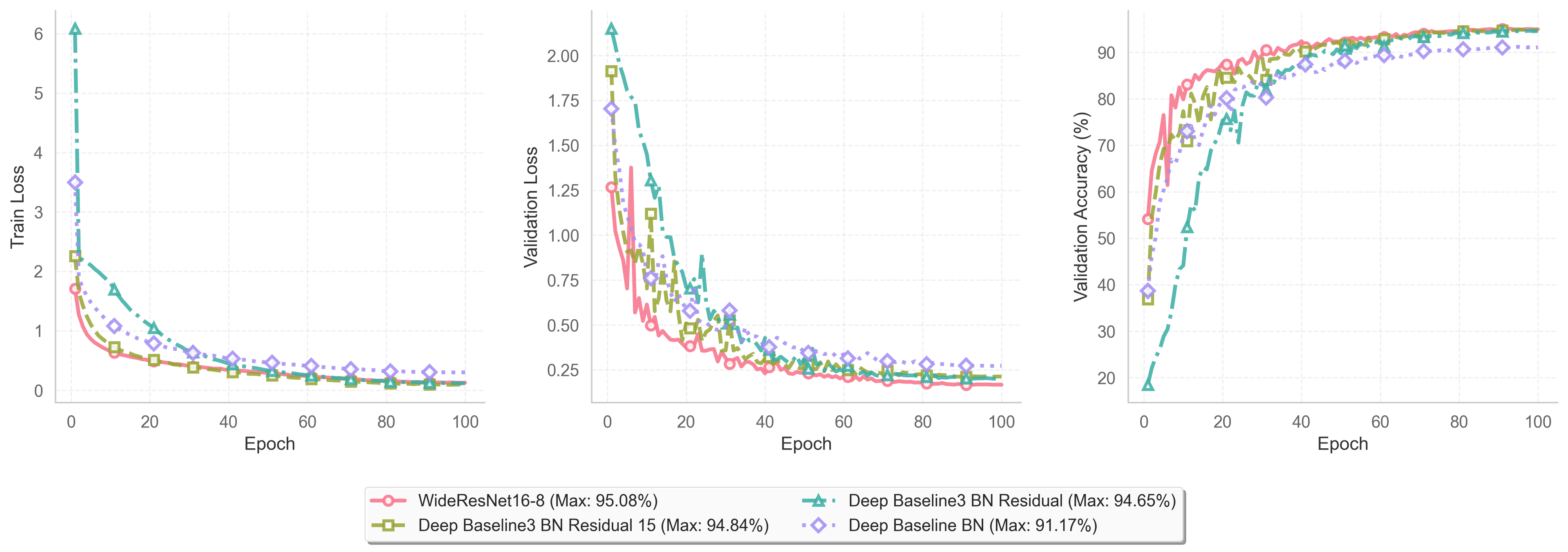
| Model | Best Acc (%) | Params | GFLOPs |
|---|---|---|---|
| DeepBaselineBN | 91.17 | 1.9 M | 0.1 |
| DeepBaselineNetBN3Residual | 94.65 | 10.4 M | 1.1 |
| DeepBaselineNetBN3Residual15 | 94.84 | 13.5 M | 0.71 |
| WideResNet-16-8 | 95.08 | 10.9 M | 1.55 |
**95.08%**의 정확도를 달성하여 더 적은 파라미터 수로 DeepBaselineNetBN3Residual15보다 높은 성능을 기록했다. 단순히 네트워크의 깊이를 늘리는 것보다 넓은 구조가 더 효율적임을 알 수 있었다.
성능 끌어올리기
Optimizer 변경 (Adam -> SGD)
Adaptive method인 Adam 대신, Momentum이 적용된 **SGD (Nesterov)**로 변경하였다. CIFAR-10과 같은 이미지 분류 태스크에서 CNN은 SGD가 Adam보다 더 나은 일반화 해를 찾는다는 연구 결과가 있다. 학습률은 0.1로 설정하였다.
- 결과: 정확도 95.22% -> 95.89% 향상.
Residual Block 구조 변경
Pre-activation Block에서 첫번째 ReLU 층을 제거하거나 마지막에 BN층을 추가해보았으나 성능이 하락하거나 미미하게 상승했다. (+ Remove 1st ReLU: 94.78%, + Last BN: 95.08%)
ASAM (Adaptive Sharpness-Aware Minimization)
일반적인 SGD는 손실값이 낮은 Global Minima를 찾지만, 해당 지점의 손실 곡선이 가파르면(Sharp) 일반화 성능이 떨어질 수 있다. 이를 해결하기 위해 파라미터 주변의 손실값까지 고려하여 평탄한(Flat) 지점을 찾는 SAM과, 파라미터 스케일에 따라 탐색 반경을 조정하는 ASAM을 도입하였다. 탐색 반경 rho=2.0으로 설정하여 실험한 결과, 유의미한 성능 향상이 관찰되었다.
| Method | Test Accuracy | Gain |
|---|---|---|
| Baseline + Augmentation | 95.89% | - |
| + ASAM (rho=2.0) | 96.34% | +0.45%p |
EMA (Exponential Moving Average)
학습 중 발생하는 파라미터의 진동을 평활화하기 위해 EMA 기법(beta=0.999)을 도입했다. 학습에는 관여하지 않고 갱신만 되며 추론 단계에서 사용된다.
- 결과: 정확도 96.34% -> 96.40% 상승.
Label Smoothing
CrossEntropy Loss 사용 시 정답 클래스에 대한 과도한 확신(Overconfidence)을 방지하기 위해 Label Smoothing(alpha=0.1)을 적용하였다. 타겟값을 1.0 -> 0.9로 낮추고 나머지에 확률을 분배하여 일반화 성능을 높였다.
- 결과: 정확도 96.40% -> 96.86% 향상.
로딩 중... Note: (이미지 대체) Hard Target vs Soft Target 확률 분포 비교 그래프
Note: (이미지 대체) Hard Target vs Soft Target 확률 분포 비교 그래프
Epoch 확장
학습 기간을 100 Epoch에서 200 Epoch로 2배 연장하여 모델이 충분히 수렴할 수 있도록 하였다.
- 결과: 96.40% -> 97.07% 향상.
WideResNet 최적화 실험 결과 요약
로딩 중...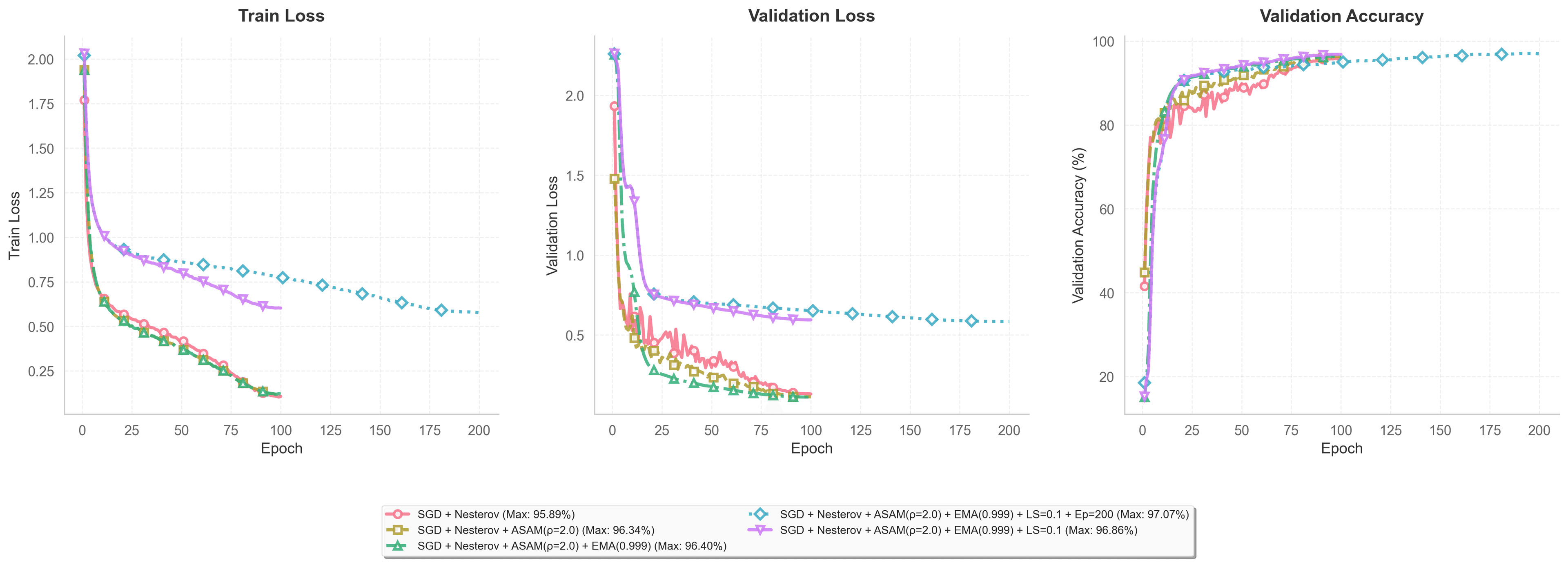
| Model Variant | Optimization & Strategy | Best Acc | Params |
|---|---|---|---|
| WRN-16-8 | -- | 95.08% | 10.9 M |
| WRN-16-8 | SGD + Nesterov (LR 0.1) | 95.89% | 10.9 M |
| WRN-16-8 | + ASAM (rho=2.0) | 96.34% | 10.9 M |
| WRN-16-8 | + ASAM + EMA | 96.40% | 10.9 M |
| WRN-16-8 | + ASAM + EMA + Label Smoothing | 96.86% | 10.9 M |
| WRN-16-8 | ASAM + EMA + LS + Epoch 200 | 97.07% | 10.9 M |
더 많은 아키텍처 탐색: PyramidNet
채널 수를 급격하게 늘리는 것보다 선형적으로 늘리는 것이 유리하다는 연구(Han et al., 2017)에 기반하여 PyramidNet-110 (alpha=150)을 도입하였다. 또한 차원 변화 시 1x1 Convolution 대신 0으로 채우는 Zero-padded Shortcut을 사용한다.
| Group Name | Output Size | Block Configuration | Channel Range |
|---|---|---|---|
| Conv1 | 32 x 32 | 3 x 3 Conv | 16 |
| Conv2_x | 32 x 32 | Block x 18 | 16 -> 66 |
| Conv3_x | 16 x 16 | Block x 18 | 66 -> 116 |
| Conv4_x | 8 x 8 | Block x 18 | 116 -> 166 |
| Classifier | 1 x 1 | Global Avg Pool -> Softmax | 166 -> 10 |
실험 결과, 추가 기법 없이도 WRN-16-8 대비 높은 **96.82%**를 기록했다.
ShakeDrop Regularization
Residual Block을 확률적으로 삭제하거나 가지(Branch)의 출력을 스케일링하는 정규화 기법인 ShakeDrop을 적용하였다. 깊은 층일수록 강한 규제를 적용하기 위해 선형적으로 확률을 조절(P_max=0.5)하였다.
로딩 중...
ShakeDrop(P_max=0.5) 적용 시 **96.9%**로 성능이 향상되었다.
PyramidNet 최종 결과 (200 Epoch)
WRN에서 사용했던 모든 최적화 전략(ASAM, EMA, LS)과 ShakeDrop을 결합하여 학습하였다.
| Model Variant | Optimization & Strategy | Best Acc |
|---|---|---|
| WRN-16-8 | ASAM + EMA + LS + Epoch 200 | 97.07% |
| PyramidNet-110 | ASAM + EMA + LS + Epoch 200 + ShakeDrop | 97.48% |
기존 최고 성능이었던 97.07%에서 **97.48%**로 +0.41%p 개선되었다.
성능 극한으로 밀어붙이기
Epoch 확장 (400 Epochs)
학습 횟수를 400 Epoch로 확장하여 추가 학습을 진행한 결과, 정확도는 **97.70%**로 상승하였다.
Ensemble & Stacking
- Ensemble: 상위 3개 모델(WRN, PyramidNet-200ep, PyramidNet-400ep)에 대해 Soft Voting을 수행하였다. 특히 PyramidNet-400ep 모델에 0.5의 가중치를 부여했을 때 **97.75%**를 달성했다.
- Stacking: 여러 모델의 로짓(Logit) 벡터를 입력으로 받아 최종 예측을 수행하는 메타 모델(3-layer MLP)을 학습시켰다. 20 Epoch 동안 학습한 결과, 최종적으로 **97.78%**의 정확도를 달성하였다.
| Strategy | Best Acc |
|---|---|
| PyramidNet-110 (400 Epochs) | 97.70% |
| Ensemble (Weighted) | 97.75% |
| Stacking (Meta Learner) | 97.78% |
추가 개선 아이디어 및 한계점
Residual Attention, ConvNextV2 등 다양한 아키텍처를 시도해보았으나 Transformer 기반 모델에 대한 탐색은 부족했다. 또한 제한된 자원으로 인해 약 10M 파라미터 크기의 모델로 실험이 제한되었다.
오류 분석 (Confusion Matrix & Top-Loss)
학습된 모델의 Confusion Matrix를 분석한 결과, Dog와 Cat 라벨 간의 오분류가 가장 빈번했다.
| Actual \ Predicted | plane | car | bird | cat | deer | dog | frog | horse | ship | truck |
|---|---|---|---|---|---|---|---|---|---|---|
| plane | 975 | 0 | 7 | 2 | 1 | 0 | 0 | 0 | 12 | 3 |
| car | 1 | 988 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 10 |
| bird | 3 | 0 | 963 | 5 | 9 | 9 | 7 | 2 | 2 | 0 |
| cat | 2 | 1 | 4 | 924 | 7 | 53 | 6 | 0 | 2 | 1 |
| deer | 0 | 0 | 6 | 6 | 979 | 4 | 3 | 2 | 0 | 0 |
| dog | 1 | 1 | 8 | 31 | 8 | 947 | 2 | 2 | 0 | 0 |
| frog | 3 | 0 | 4 | 3 | 1 | 0 | 988 | 1 | 0 | 0 |
| horse | 2 | 0 | 2 | 4 | 6 | 4 | 0 | 982 | 0 | 0 |
| ship | 6 | 4 | 2 | 0 | 0 | 0 | 1 | 0 | 984 | 3 |
| truck | 1 | 17 | 0 | 1 | 0 | 0 | 0 | 0 | 4 | 977 |
Note: cat(924)과 dog(947)의 정확도가 상대적으로 낮으며 서로 혼동하는 경향이 있다.
정성적 오류 분석
테스트 단계에서 손실값이 가장 높은 샘플들을 시각화해 본 결과, 모델이 예측에 실패했지만 인간의 눈으로 보았을 때는 모델의 예측이 더 타당해 보이는 경우가 발견되었다.
로딩 중...
로딩 중... Caption: 모델은 frog라고 예측했으나 정답 라벨은 cat인 데이터. (CIFAR-10 데이터셋의 내재적 오류 가능성)
Caption: 모델은 frog라고 예측했으나 정답 라벨은 cat인 데이터. (CIFAR-10 데이터셋의 내재적 오류 가능성)
이는 CIFAR-10 데이터셋에 약 0.54%의 잘못된 레이블이 존재한다는 선행 연구(Northcutt et al.)와 일치하는 결과로, 성능 향상의 한계가 데이터셋 자체의 노이즈에 기인할 수 있음을 시사한다.